Comments
sukhmel 1 point today
I find it more interesting to count series of the same number, and some autocorrelation. But since there's a code sample I may try to plot that myself later
1 RonSijm
7 points
tomorrow
RonSijm
7 points
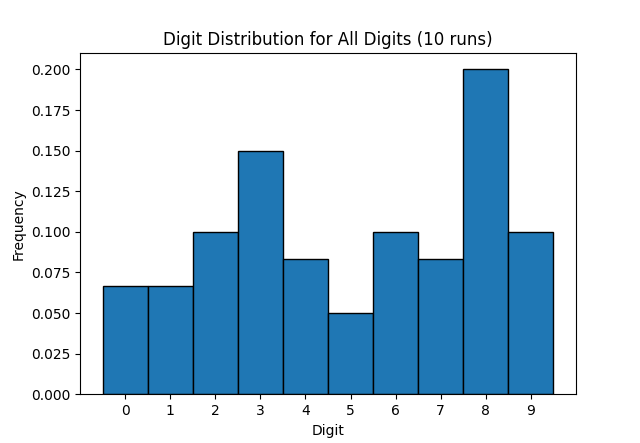
tomorrowPretty cool to show that sample size matters a lot during testing...
Sample size = 10: "There's 20% 8! WTF, should be 10%"
Sample size = 10k+: "Oh wait nevermind"7Technoguyfication 11 points in 2 days
For anyone who doesn’t read the article, the biases shown in the thumbnail are not the final result. After doing a million runs, every digit had close to the same probability of appearing.
11onlinepersona 8 points in 2 days
Love it! He had an assumption, created a method of testing that assumption, tried it multiple times, was proven wrong and accepted it.
Now, if more people could operate this way...
8